Ogni giorno sempre più modelli vengono sviluppati per creare nuove funzionalità. Sfortunatamente non appena si ha a che fare con più modelli, dataset e data scientists le cose si complicano. Ciascun esperimento ha molte dipendenze e l’effetto “changing anything changes everything” rende difficile tenere traccia di cosa sta accadendo. Una soluzione ML-driven richiede di tracciare come un modello è stato prodotto, scelto, distribuito e come si comporta in produzione: il modello di ML è solo un pezzo del puzzle. Simone ci mostrerà alcuni dei problemi più comuni che grosse AI companies hanno nel sviluppare soluzioni basate sul ML e come risolverli.
Simone Merello, inizia la sua carriera come ricercatore in ambito ML presso l’università NTU di Singapore. Successivamente esce dall’ambito accademico per diventare prima Research Scientist ed ora Head of Deep AI presso Perceptolab.
Ecco l’agenda del sesto incontro, a cavallo tra la frontiera della ricerca e la didattica sui nostri dataset.
Mercati Finanziari: affrontare con il Machine Learning un un problema davvero complesso
Simone Merello, specialista in AI for Finance presso Nanyang Technological University of Singapore
Simone Merello a DatasScienceSeed
Predire l’andamento del mercato finanziario è un problema complesso, al punto che non ne è ancora chiara la fattibilità stessa. Sono state tentate tutte le tecniche di Machine Learning ed ogni sorta di reti naurali, ma i problemi sono tanti ed a tanti livelli. Simone ci ha spiegato come ha affrontato questo problema, presentandoci le tecniche usate nelle ultime ricerche, in un percorso tra le difficoltà e le opportunità valido per molte classi di problemi.
Ecco le slides di Simone, sotto forma di Google Doc
Attenzione! Audio Challenge!
L’audio del talk è molto disturbato a causa di un problema tecnico al sistema della sala nel giorno della ripresa. Ce ne scusiamo… nonostante gli sforzi in post produzione dei ragazzi del service la qualità audio è molto inferiore al livello che vorremmo tenere. Ma possiamo trasformare questo problema in opportunità!! Siamo certi che con il Machine Learning / Deep Learning si può ulteriormente ripulire questo audio. Chi vuole tantare? I tentativi più o meno riusciti saranno presentati in un meetup!
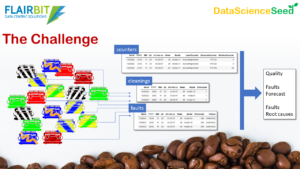
Caffè con Pandas: cosa abbiamo imparato dal Coffe Machines Dataset
A Febbraio i ragazzi di Flairbit ci hanno offerto un problema di manutenzione predittiva su una flotta di macchine del caffè professionali. Ci abbiamo lavorato e siamo pronti a mostrarne i risultati alla community. Marcello ha parlato di Pandas, la libreria Python che non può mancare nella cassetta degli attrezzi del data scientist, per passare da un dataset selvaggio ad un docile datasetche daremo in pasto ad un modello di machine learning di tipo “classico” ma per niente banale, il LightGBM, Andrea ha poi mostrato come costruire ed addestrare una rete neurale feed forward per lo stesso dataset, ottimizzandone gli iperparametri fino ad identificare la configurazione ottimale.
Riusciremo a prevenire i guasti ed a meritarci un buon caffè?
Andrea Boero eSimone Merello discutono di architetture neurali mentre gli altri si mangiano la focaccia
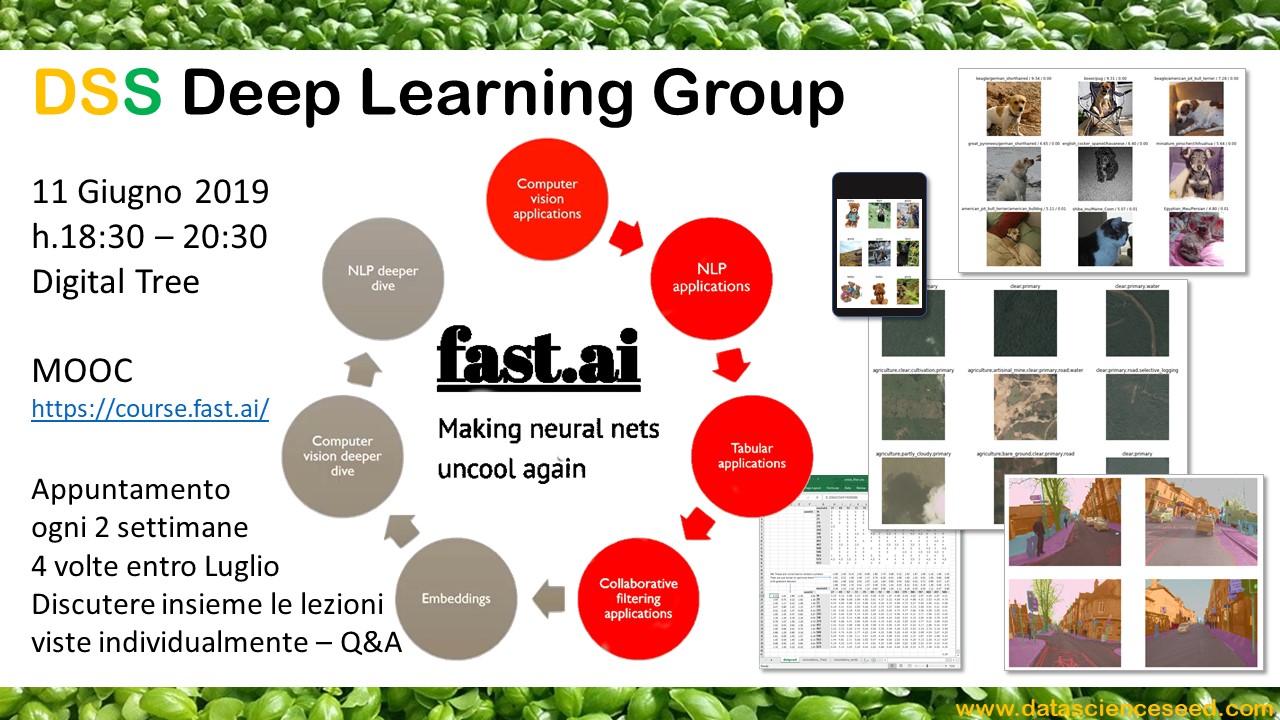
Deep Learning Group
Abbiamo presentato nel meetup il Learning Group su Deep Learning che partirà con la prima sessione l’11 Giugno, alle 18.30 presso Digital Tree.
Seguiremo il corso Practical Deep Learning for coders, di Fast.ai, e ci incontreremo ogni due settimane per discutere delle lezioni seguite online, del codice presentato, delle difficoltà incontrate e magariper provare a cimentarci con qualche progetto reale.


 Ogni giorno sempre più modelli vengono sviluppati per creare nuove funzionalità. Sfortunatamente non appena si ha a che fare con più modelli, dataset e data scientists le cose si complicano. Ciascun esperimento ha molte dipendenze e l’effetto “changing anything changes everything” rende difficile tenere traccia di cosa sta accadendo. Una soluzione ML-driven richiede di tracciare come un modello è stato prodotto, scelto, distribuito e come si comporta in produzione: il modello di ML è solo un pezzo del puzzle. Simone ci mostrerà alcuni dei problemi più comuni che grosse AI companies hanno nel sviluppare soluzioni basate sul ML e come risolverli.
Ogni giorno sempre più modelli vengono sviluppati per creare nuove funzionalità. Sfortunatamente non appena si ha a che fare con più modelli, dataset e data scientists le cose si complicano. Ciascun esperimento ha molte dipendenze e l’effetto “changing anything changes everything” rende difficile tenere traccia di cosa sta accadendo. Una soluzione ML-driven richiede di tracciare come un modello è stato prodotto, scelto, distribuito e come si comporta in produzione: il modello di ML è solo un pezzo del puzzle. Simone ci mostrerà alcuni dei problemi più comuni che grosse AI companies hanno nel sviluppare soluzioni basate sul ML e come risolverli.